
파게로그
인덱스 본문
소개
index란... 파일에 있는 레코드를 찾아주는 보조적인 파일.
- 색인은 정렬되어 있음
- 검색을 빨리 하도록 도와줌
- 자료 파일에 비해 상대적으로 양이 적음
순서 구조의 인덱스
- 인덱스 필드와 주소 값으로 구성된 엔트리들의 모임
- 초기
기본적인 색인 기법을 다단계로 이용하여 ISAM(Indexed Sequential Access Method)이라는 색인 순차 파일이 보급됨
ISAM은 정적. 자료의 추가와 삭제에 따라서 색인 구조가 증대하고 수축하는 동적인 색인인 B-tree 색인
해싱 구조의 인덱스
- 키 값에 의하여 레코드의 위치를 직접 찾아주는 기법
------
색인의 형태
색인의 분류
기본 색인 vs 보조 색인 vs 클러스터링 색인
- primary index(기본 색인): 기본 키로 검색
- 탐색 절차
기본 키로 구성됨
- 특징
작은 색인 크기 - secondary index(보조 색인): primary index가 있는 파일을 보조
- 탐색 절차
복수 튜플 검색
- 특징
큰 색인 크기
중복 허용
부분 탐색 - clustering index(클러스터링 색인): 키가 아닌 필드에 따라 물리적으로 정렬됨
- 탐색 절차
키에 의한 직접 탐색
- 특징
키가 아닌 속성을 위한 물리적 순서
중복 허용
단일 단계 색인 vs 다단계 색인
밀집 색인 vs 희소 색인
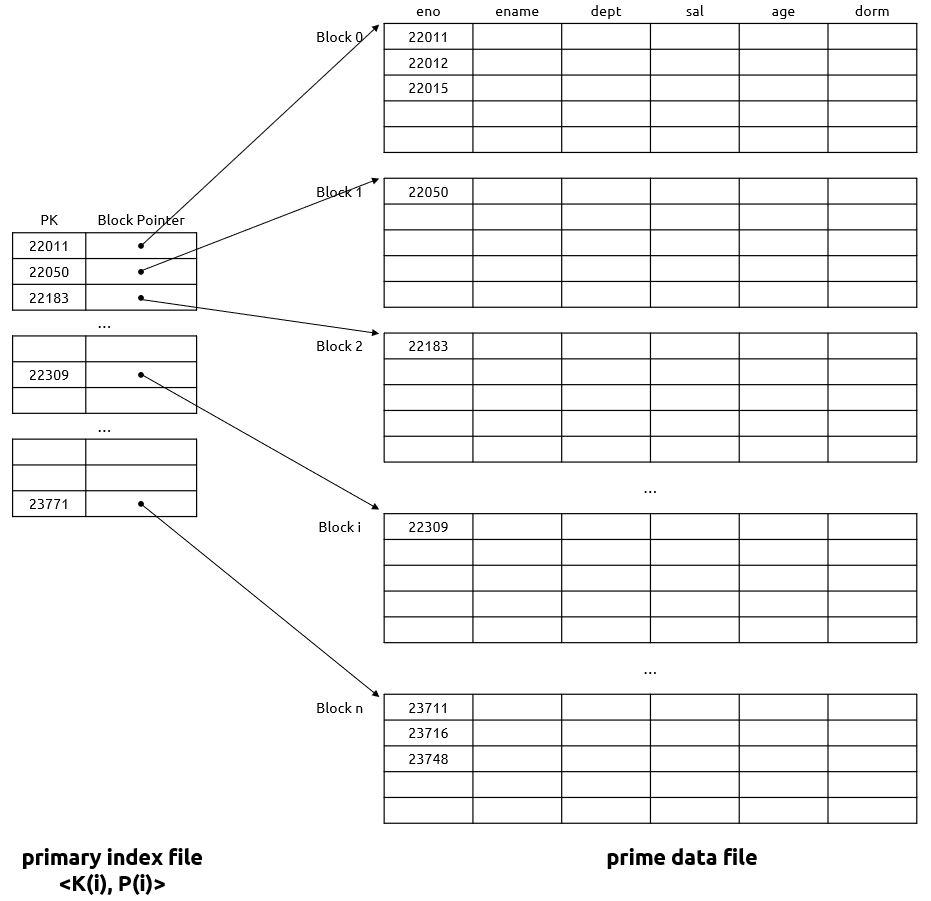
기본 색인
기본 키를 기준으로 레코드를 검색해주는 보조 파일
기본 키 속성과 해당 레코드가 저장된 블록의 주소로 구성됨 eg. <사번, 블록 포인터>
기본 색인 자체는 순서 파일이므로 특정한 레코드를 찾기 위해서는 기본 색인을 순서대로 읽어야 함
블록의 주소는 원하는 레코드가 저장된 블록에서 첫 번째 레코드가 저장된 주소 = anchor record / block anchor
블록에는 블록킹 인수만큼의 레코드 수가 저장되어 있음
물리적으로 정렬된 파일에서 사용되므로 레코드의 추가와 삭제 시에 문제가 있음
- 레코드 추가: 앵커 블록이 바뀌므로 복잡
- 레코드 삭제: 삭제 표시자로 해결
보조 색인
기본 색인이 있는 파일에서 부수적인 검색을 도와주는 목적으로 만든 파일
기본 색인이 있으므로 보조 색인의 순서는 물리적인 파일의 레코드 순서와는 무관함
중복을 허용하므로 부분 검색에 유리함.
여러 개의 보조 색인이 존재할 수 있음
기본색인 없이 보조색인을 만들 수도 있음
즉 <보조 키, 블록 포인터>에서 서로 다른 블록 포인터가 동일한 블록을 가리킬 수 있음
유일한 값을 가진 보조 색인의 경우...(밀집 색인)
유일성을 가진 속성을 보조 색인에 사용하면 밀집 색인인 듯 -> 보조 색인 엔트리의 수는 사원 레코드의 수와 동일
기본 색인은 유일성을 가졌지만 아닌 듯 -> 기본 색인의 엔트리의 수는 블록 개수만큼일 듯
중복 값을 가진 보조 색인의 경우...
2단계 색인을 구성하게 됨
색인 엔트리가 <부서번호, bucket pointer>로 구성
버켓의 엔트리는 <부서번호, block pointer>로 구성
버켓: 특정한 부류의 자료들을 모아두는 디스크 안의 논리적인 공간. 하나의 버켓이 여러 개의 페이지를 포함할 수 있음. 하나의 버켓에는 모든 소속부서의 사원에 대한 레코드들이 저장된 블록번호가 저장되어 있음
하나의 버켓은 여러 개의 블록에 나뉘어 저장될 수 있음


클러스터링 색인
클러스터링 필드: 파일 안의 레코드들이 키가 아닌 필드에 따라 물리적으로 정렬되어 있을 때, 이 필드
클러스터링 색인: 클러스터링 필드로 만든 색인
클러스터링 색인과 블록의 주소로 구성됨
중복이 가능하여 색인의 크기가 작음
여러 레코드들이 저장된 블록을 검색하는 데 효율적
보조 색인은 기본 키가 있어야 존재하기 때문에 클러스터링 색인과 무관함
