
파게로그
[SQL] PIVOT, UNPIVOT 본문
using pivot and unpivot
pivot_clause
Pivot and Unpivot
www.oracle.com/technical-resources/articles/database/sql-11g-pivot.html
PIVOT
DECODE
SELECT deptno,
SUM(DECODE(title, 'LEADER', sal)) "LEADER",
SUM(DECODE(title, 'COOPERATOR', sal)) "COOPERATOR",
SUM(DECODE(title, 'RESEARCHER', sal)) "RESEARCHER",
SUM(DECODE(title, 'ANALYST', sal)) "ANALYST"
FROM emp
GROUP BY deptno;


PIVOT
SELECT * FROM (SELECT deptno, sal FROM emp)
PIVOT (SUM(sal) FOR deptno IN (10, 20, 30));

결과에 필요한 column만, 즉 deptno와 sal만 SELECT하여야 한다.
SELECT * FROM (SELECT title, sal FROM emp)
PIVOT (SUM(sal) FOR title IN ('ANALYST' "ANALYST", 'RESEARCHER' "RESEARCHER", 'COOPERATOR' "COOPERATOR"));

AS를 통해 column명에 표시되는 따옴표를 없앨 수 있다.
UNPIVOT
UNPIVOT
CREATE TABLE stock (
ename VARCHAR2(10),
pencil NUMBER(5),
ink NUMBER(5),
eraser NUMBER(5)
);
INSERT INTO stock VALUES ('김철수', 5, 8, 6);
INSERT INTO stock VALUES ('차도남', 6, 7, 8);
INSERT INTO stock VALUES ('허윤지', 8, 7, 7);
SELECT *
FROM stock
UNPIVOT (건수 for 아이템 in (pencil AS 'PENCILS', ink AS 'INKS', eraser AS 'ERASERS'));
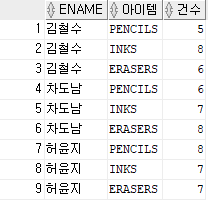
UNPIVOT은 PIVOT의 반대 연산인 것은 아니라서 단순히 열을 행으로 바꾸어줄 뿐이다. 따라서 집계 함수의 결과인 데이터를 원래의 데이터로 되돌리는 것도 불가능하다.
null 데이터는 UNPIVOT 결과에서 출력되지 않으나, UNPIVOT INCLUDE NULLS로 결과에 포함할 수 있다.
Pivot and Unpivot
www.oracle.com/technical-resources/articles/database/sql-11g-pivot.html

관계형 테이블은 column-value의 쌍으로서 표에 표현된다.
각각의 고객에 대해서 존재하는 record는 고객의 아이디, 이름, 주 코드, 구입 횟수를 보여준다. TIMES_PURCHASED column은 고객이 물건을 구매할 때마다 업데이트된다.
각 주에 대한 구입 빈도 보고를 하고 싶다는 경우를 상정해보자. 즉 구입횟수가 1회인 고객, 2회인 고객, 3회인 고객 등이 각 주마다 몇 명이 있는지 알고 싶은 것이다. 보통의 SQL에서는 다음과 같은 쿼리를 작성할 수 있다.
SELECT state_code, times_purchased, COUNT(state_code) CNT
FROM customers
GROUP BY state_code, times_purchased
ORDER BY state_code;

하지만 위 테이블은 가독성이 나쁘다. crosstab 보고를 통해서 마치 스프레드시트처럼, 데이터를 수직으로, 주를 수평으로 구성함으로써 가독성을 향상시킬 수 있다.
SELECT
times_purchased,
COUNT(DECODE(state_code, 'AK', 1)) "AK",
COUNT(DECODE(state_code, 'NJ', 1)) "NJ",
COUNT(DECODE(state_code, 'NY', 1)) "NY",
COUNT(DECODE(state_code, 'OK', 1)) "OK",
COUNT(DECODE(state_code, 'TX', 1)) "TX",
COUNT(DECODE(state_code, 'WY', 1)) "WY"
FROM customers
GROUP BY times_purchased
ORDER BY times_purchased;

하지만 이러한 쿼리는 너무 직관적이지 못한데, 11g부터는 PIVOT 연산을 통해 보다 간결하고 직관적으로 작성할 수 있다. 아래에서 pivot point는 COUNT(state_code)이며, 즉 header row가 state_code가 된다.
SELECT * FROM (SELECT times_purchased, state_code FROM customers)
PIVOT (COUNT(state_code) FOR state_code IN ('AK', 'NJ', 'NY', 'OK', 'TX', 'WY'))
ORDER BY times_purchased;
참고로 pivot point가 COUNT(state_code)가 아니라 COUNT(times_purchased)가 되면 다음과 같은 결과를 얻을 수 있다.
SELECT * FROM (SELECT times_purchased, state_code FROM customers)
PIVOT (COUNT(times_purchased) FOR times_purchased IN (1,2,4,5,8,11,19))
ORDER BY state_code;

'콤퓨타 왕기초 > SQLD/JDBC/Oracle DB' 카테고리의 다른 글
| SQLD 시험 후기 (0) | 2021.09.05 |
|---|---|
| [SQL] ROWNUM, simple TOP-n queries (0) | 2021.04.02 |
| [SQL] 데이터 분석 함수 (0) | 2021.04.01 |
| [SQL] 집계함수(aggregate functions) (0) | 2021.03.31 |
| [SQL] SQL로 IF문 구현 (0) | 2021.03.31 |


